CSAPP-2-1:程序的机器级表示
程序的机器级表示
程序编码概论
术语介绍
假设一个C程序有两个文件p1.c和p2.c,我们使用gcc编译这些代码,会经过以下步骤:
- C预处理扩展源代码,插入所有用#include命令指定的文件,并扩展所有用#define声明指定的宏;
- 编译器产生两个源文件的汇编代码,名字分别为p1.s和p2.s;
- 汇编器将汇编代码转化为二进制目标代码文件p1.o和p2.o;
- 链接器将目标代码文件和实现库函数的代码合并,并产生最终的可执行文件p。
代码形式分为两种:
- 机器代码:byte-level的文件,包括目标代码以及可执行代码文件,目标代码中包含所有指令的二进制表示,但是还没有填入全局值的地址。
- 汇编代码:是机器代码的文字表述。
对于机器级编程来说,有两种抽象尤为重要:
- 第一种是由 指令集体系结构或指令集架构(Instruction Set Architecture, ISA) 来定义机器级程序的格式和行为,它定义了处理器状态、指令的格式以及每条指令对状态的影响。大多数ISA,包括x86-64,将程序的行为描述成好像每条指令都是按顺序执行的。
- 第二种是机器级程序使用的内存地址是虚拟地址,提供的内存模型看上去是一个非常大的字节数组,存储器系统的实际实现是将多个硬件存储器和操作系统软件组合起来,在后面第九章会讲到。
在整个编译过程中,编译器会完成大部分的工作,将C语言提供的相对抽象的执行模型表示的程序转化为汇编代码,其主要特点是它用可读性更好的文本格式表示。
x86-64的机器代码和C代码差别非常大,一些通常对C语言程序员隐藏的处理器状态都是可见的:
- 程序计数器(通常称为PC,在x86-64中用%rip表示)给出将要执行的下一条指令在内存中的地址。
- 整数寄存器文件包含16个命名的位置,分别存储64位的值。这些寄存器可以存储地址或整数数据。有的寄存器被用来记录重要的程序状态,而其他的寄存器用来保存临时数据,例如过程的参数和局部变量或返回值。
- 条件码寄存器保存着最近执行的算术或逻辑指令的状态信息
- 一组向量寄存器可以存放一个或多个整数或浮点数值。
虽然C语言提供了模型,可以在内存中声明和分配各种数据类型的对象,但是机器代码只是简单地将内存看成一个很大的按字节寻址的数组,C语言中的聚合数据类型,例如数组和结构不存在于机器级代码,即使对于标量数据类型,汇编代码也不区分符号数与无符号数,不区分各种类型的指针,甚至不区分指针和整数。
程序内存包含:程序的可执行机器代码,操作系统需要的一些信息,用来管理过程调用和返回的运行时栈,以及用户分配的内存块。程序内存用虚拟地址来寻址,例如x86-64的虚拟地址是由64位的字来表示的,操作系统负责管理虚拟地址空间,将虚拟地址翻译成实际处理器内存中的物理地址。
一条机器指令只执行一个非常基本的操作,编译器必须产生这些指令的序列,从而实现程序结构。
代码示例
假设我们写了一个C语言代码mstore.c
long mult2(long, long);
void multstore(long x, long y, long *dest) {
long t = mult2(x,y);
*dest = t;
}
使用gcc命令gcc -Og -S mstore.c可以产生汇编代码文件,包含以下几行:
multstore:
pushq %rbx
movq %rdx, %rbx
call mult2
movq %rax, (%rbx)
popq %rbx
ret
如果我们使用命令gcc -Og -c mstore.c,可以产生目标代码文件,它是二进制格式的,可以利用GDB命令(gdb) x/14xb mulstore查看。由此可见,机器对产生这些指令的源代码一无所知。
要查看机器代码文件的内容,有一类称为 反汇编器(disassembler)的程序非常有用,这些程序根据机器代码产生一种类似于汇编代码的格式,在Linux系统中可以使用objdump -d mstore.o命令实现,结果如下:
0000000000000000 <multstore>:
0: 53 push %rbx
1: 48 89 d3 mov %rdx, %rbx
4: e8 00 00 00 00 callq 9 <multstore+0x9>
9: 48 89 03 mov %rax, (%rbx)
c: 5b pop %rbx
d: c3 retq
其中一些关于机器代码和他的反汇编表示特性值得注意:
- x86-64的指令长度从1到15个字节不等。
- 设计指令格式的方式是从某个给定位置开始,可以将字节唯一解码成机器指令。例如,只有
pushq %rbx是以字节值53开头的。 - 反汇编器只是基于机器代码文件中的字节序列来确定汇编代码,它无需访问源代码或汇编代码。
- 反汇编器使用的指令命令规则与gcc生成的汇编代码有细微差别,它省略了后缀的大小指示符。
- 源程序所有名称在汇编代码级别完全消失,变成了寄存器或内存的某个位置。
链接器的任务之一就是为函数调用找到匹配的函数的可执行代码的位置,将代码的地址移到不同的地址范围中并在callq指令调用中填入需要使用的地址;另外,它也会插入一些nop指令使得函数代码变为16字节,使得就存储器系统性能而言,能更好地放置下一个代码块。
数据格式
由于是从16位体系结构扩展到现在的,Intel用术语 字(word)来表示16位(2字节)数据类型,称32位为 双字(double words),称64位为 四字(quad words),下图给出了语言基本数据类型对应的x86-64表示。
| C声明 | Intel数据类型 | 汇编代码后缀 | 大小(字节) |
| char | 字节 | b | 1 |
| short | 字 | w | 2 |
| int | 双字 | l | 4 |
| long | 四字 | q | 8 |
| char* | 四字 | q | 8 |
| float | 单精度 | s | 4 |
| double | 双精度 | l | 8 |
访问信息
一个x86-64的CPU包含一组16个存储64位值的 通用目的寄存器,用于存储整数数据和指针,如下图所示。

最初的8086中有8个16位的寄存器,即图中的%ax到%sp,它们的名字反映了不同的用途,分别是accumulate, base, counter, data, source index, destination index, base pointer, stack pointer.
目前它们已经和过去的功能几乎毫无关系,只是保留了名字。新扩充的8个寄存器则命名为%r8到%r15。
图中嵌套的方框表明,指令可以对这些寄存器的低位字节存放的不同大小的数据进行操作。当指令以寄存器为目标时,对于生成小于8字节结果的指令,有两个规则:
- 生成1字节和2字节数字的指令会保持剩下的字节不变,
- 生成4字节数字的指令会把高位4个字节置为0。
在常见的程序里,不同的寄存器扮演着不同的角色,有一组标准的变成规范控制着如何使用寄存器来管理栈、传递函数参数、从函数返回值以及存储局部和临时数据。
操作数指示符
大多数指令有一个或多个 操作数(operand),指示出执行一个操作要使用的源数据值以及放置结果的目的为止。源数据值可以以常数形式给出,或是寄存器或内存中读出,结果可以存放在寄存器或者内存中。因此,操作数分为3种类型:
- 立即数(immediate)用来表示常数值,书写方式为$后面跟一个用C表示法表示的整数,例如
$-557, $0x1F - 寄存器(register)表示某个寄存器的内容,我们用符号 $r_a$ 来表示任意寄存器a,用引用 $R[r_a]$ 表示它的值,这是将寄存器集合看成一个数组 $R$,用寄存器标识符作为索引。
- 内存引用,它会根据计算出来的地址访问某个内存位置,我们用符号$M_b[Addr]$ 表示对存储在内存中从地址Addr开始$b$个字节值的引用。
如下图所示,有多种不同的寻址模式,允许不同形式的内存引用。其中最底部的 $Imm(r_b,r_i,s)$ 为最常用的形式,这里基址寄存器 $r_b$ 可以是任意寄存器,变址寄存器 $r_i$ 可以是除 \%rsp 外的任意寄存器,s必须为1、2、4或者8。有效地址被计算为 $Imm+ R[r_b]+R[r_i]\cdot s$。
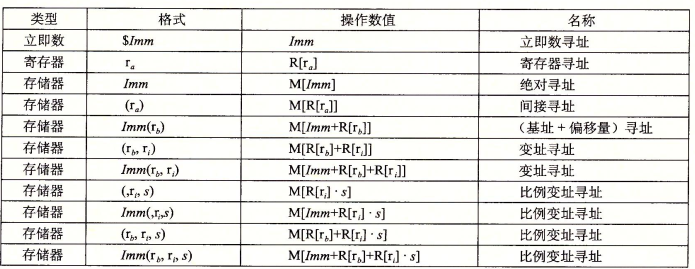
数据传送指令
最简单形式的数据传送指令为MOV类,这类指令把数据从源位置复制到目的位置,如下图所示:
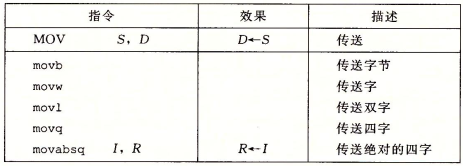
源操作数指定的值可以是立即数,也可以存储在寄存器或者内存中。目的操作数指定一个位置,要么是一个寄存器,要么是一个内存地址。 x86-64限制传送指令的两操作数不能都指向内存为止,如果想这样做需要先将源值加载到寄存器然后再写入目的位置。
大多数情况中MOV指令只会更新目的操作数指定的那些寄存器字节或内存位置,唯一的例外是 movl指令以寄存器作为目的时,它会把该寄存器的高位4字节设置为0。这是由于x86-64惯例为任何为寄存器生成32位值的指令都会把高位设置为0。
另外,常规的movq指令以立即数为源操作数时,只能表示32位补码数字再将其扩展到64位的值,movabsq指令能够以任意64位立即数值作为源操作数,并且只能以寄存器作为目的。
下面两个图记录的是另外两类数据移动指令,在将较小的源值复制到较大的目的时使用。

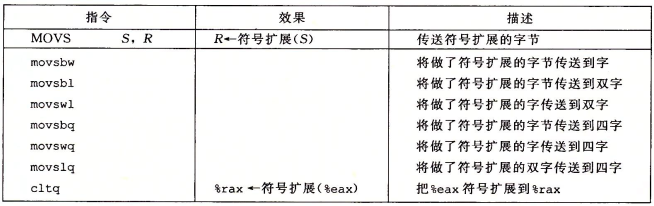
注意到并没有一条明确的指令把4字节源值扩展到8字节目的,因为这个可以依靠movl指令实现。
例子:
movabsq $0x0011223344556677, %rax |
%rax = 0x0011223344556677 |
movb $-1, %al |
%rax = 0x00112233445566FF |
movw $-1, %ax |
%rax = 0x001122334455FFFF |
movl $-1, %eax |
%rax = 0x00000000FFFFFFFF |
movq $-1, %rax |
%rax = 0xFFFFFFFFFFFFFFFF |
反例:
movb $0xF, (%ebx) |
内存引用要用4字寄存器 |
movl %rax, (%rsp) |
movl改为movq,MOV指令以源操作数字长为准 |
movw (%rax), 4(%rsp) |
两操作数不能同时为内存引用 |
movb %al, %sl |
不存在%sl这个寄存器 |
movq %rax, $0x123 |
立即数不能作为目的地址,去掉$是可以的 |
movl %eax, %rdx |
两寄存器的大小必须一致 |
movb %si, 8(%rbp) |
movb改为movw |
注释:
- 从小字长复制到大字长寄存器或内存都需要扩展;
- MOV指令一定确保能将源操作数完整地传送;
- 从大字长类型内存复制到小字长内存需要先利用寄存器存值,再用寄存器的低位传递到小字长类型的内存中;
例子:
int *sp, char *dp, *dp = (char) *spmovl (%rdi), %eax movb %al, (%rsi)char *sp, int *dp, *dp = (int) *spmovsbl (%rdi), %eax movl %eax, (%rsi)
压入和弹出栈数据
栈遵循后进先出的原则,弹出的值永远是最近被压入而且仍然在栈中的值。栈可以实现为一个数组,总是从数组的一端插入和删除元素,称为栈顶。
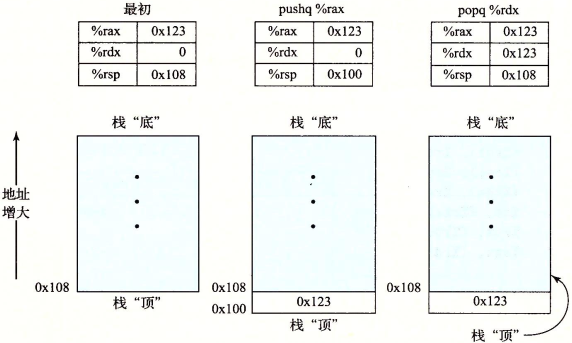
在x86-64中栈存放在内存的某个区域,如下图所示,栈向下增长。对栈可以进行两个操作:
pushq %rbp指令首先将栈指针减8,然后将值写入新的栈顶位置,等价于subq $8, %rsp movq %rbp, (%rsp)popq指令首先从栈顶位置读出数据,再将栈指针加8,等价于movq (%rsp), %rax addq $8, %rsp

算术和逻辑操作
操作指令主要分为四组:加载有效地址、一元操作、二元操作和移位,如下图所示:
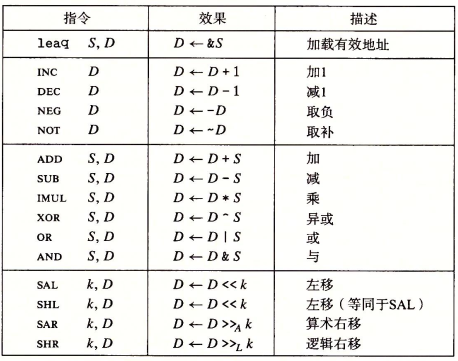
加载有效地址
加载有效地址(load effective address)指令leaq实际上是movq指令的变形,它的指令形式是从内存读数据到寄存器,但 实际上它根本没有引用该内存,而是将有效地址写入到目的操作数。另外,他也可以简洁地表述普通的算术操作,例如,如果寄存器\%rdx存有 $x$,那么leaq 7(%rdx,%rdx,4), %rax就是将寄存器 \%rax的值设置为 $5x+7$。
leaq指令的目的操作数必须是一个寄存器,下面将movq,leaq与数组进行类比:
movq相当于array[i],movq (%rdi,%rsi,8), %rbp是将源内存地址的值传给\%rbp;
leaq相当于&array[i],leaq (%rdi,%rsi,8), %rbp是将源内存地址直接传给\%rbp。
一元和二元操作
二元操作的第二个操作数既是源又是目的,类似于x-=y,第一个操作数可以是立即数、寄存器或者内存,第二个操作数可以是寄存器或者内存, 当第二个操作数为内存时,处理器必须从内存读出值,执行操作,再把结果写回内存。
移位操作
移位量可以是一个立即数,或者放在单字节寄存器\%cl中。(这些指令很特别,因为只允许以这个特定的寄存器为操作数。)
原则上来说1个字节的移位量使得移位量的编码范围可以达到 $2^8-1=255$,移位操作对 $w$ 位长的数据值进行操作,移位量是由\%cl寄存器的低m位决定的,这里 $2^m=w$,高位会被忽略。
例如,当寄存器\%cl的十六进制的值为0xFF时,指令salb会左移7位,而指令salw会左移15位,salq会左移63位。
移位操作的目的操作数可以是一个寄存器或是一个内存位置。
特殊的算术操作
两个64位有符号或无符号整数相乘需要128位来表示,Intel把16字节的数称为 八字(oct word),下图为支持两个64位数字的全128位乘积和除法的指令:

imulq指令有两种不同形式:
- 一种是前面的双操作数乘法指令,实现了前一章的操作 $\times_{64}^u, \times_{64}^t$;
- 另外一种是上图中的单操作数乘法指令—-一个是无符号数乘法(
mulq),而另一个是补码乘法(imulq),这两种指令都要求都要求一个参数必须在寄存器\%rax中,而另一个作为指令的源操作数给出,最后乘积存放在寄存器\%rdx(高64位)和\%rax(低64位)中。 例:typedef unsigned __int128 uint128_t; void store_uprod(uint128_t *dest, uint64_t x, uint64_t y){ *dest = x * (uint128_t) y; }
GCC生成的汇编代码如下:
% dest in %rdi, x in %rsi, y in %rdx
store_uprod:
movq %rsi, %rax Copy x to multiplicand
mulq %rdx Multiply by y
movq %rax, (%rdi) Store lower 8 bytes at dest
movq %rdx, 8(%rdi) Store upper 8 bytes at dest+8
因为我们针对的是小端法机器,所以高位字节存储在大地址。
类似的,有符号除法指令idivl将寄存器\%rdx(高64位)和\%rax(低64位)中的128位数作为被除数,而 除数作为指令的操作数给出,指令将商存在寄存器\%rax中,将余数存在寄存器\%rdx中。
对于大多数64位除法应用来说,被除数也常常是64位的值,这个时候值应该存在\%rax中,\%rdx的位应该设置为0(无符号运算)或者\%rax的符号位(有符号运算),这个操作可以用cqto完成。 以有符号64位整数除法运算为例:
void remdiv(long x, long y, long *qp, long *rp){
long q = x/y;
long r = x%y;
*qp = q;
*rp = r;
}
GCC编译得到如下汇编代码:
% x in %rdi, y in %rsi, qp in %rdx, rp in %rcx
remdiv:
movq %rdx, %r8
movq %rdi, %rax
cqto
idivq %rsi
movq %rax, (%r8)
movq %rdx, (%rcx)
ret
上述代码中,必须先把qp保存到另一个寄存器中,因为除法操作需要使用。
再考虑无符号64位数的除法:
void remdiv(unsigned long x, unsigned long y,
unsigned long *qp, unsigned long *rp){
unsigned long q = x/y;
unsigned long r = x%y;
*qp = q;
*rp = r;
}
GCC编译得到如下汇编代码:
% x in %rdi, y in %rsi, qp in %rdx, rp in %rcx
remdiv:
movq %rdx, %r8
movq %rdi, %rax
movl $0, %edx
divq %rsi
movq %rax, (%r8)
movq %rdx, (%rcx)
ret